深入淺出 GraphQL Pagination 實作


嗨,好久不見!今年到現在的文章產量真的是低到可憐,有些東西一直很想要寫都拖了許久甚至懶得寫,但覺得還是要秉持自己當初寫部落格的初衷,為自己遇到問題留下一些腳印,幫助自己說不定可以幫助到和我遇到一樣問題的人。
從 GraphQL 問世之後,對於它一直處於一個似懂非懂的狀態,以前只有寫過一些簡單的應用感受 GraphQL,並沒有在真實的產品上做到任何的應用,剛好現在公司很早就導入了 GraphQL,產品都大量的採用 GraphQL,讓我有這個機會可以更進一步認識。
前陣子被分配到一個任務是關於實作分頁(Pagination)的任務,理所當然是利用 GraphQL 來實作,一開始以為產品中應該已經有人實作過相關的功能了,但一查之下發現都沒有 😂,所以必須自己從頭開始研究,接下來想分享一些我在研究和實作的一些心得。
分頁的類型
Offsets
以前自己在學習寫網頁時,關於如何實作分頁這件事,只知道使用 OFFSET + LIMIT 的方式來完成,但那時候對於效能並沒有什麼很好的概念,後來才知道 OFFSET + LIMIT 在資料量大的時候會非常地緩慢,也會造成資料庫的極大負擔。
這個原因主要是當資料量大時,你所設定的 OFFSET 實際上資料庫還是會一筆一筆的去讀取,直到讀到你所設定的「偏移量」,但前面所有讀取的根本就用不到,這些都造成了計算的浪費。以下是一個範例:
SELECT*FROMartistsWHEREcountry = 'USA'ORDER BYid DESCLIMIT 5 OFFSET 5;
假設我有一個 artists 的 table,我需要查詢藝人的 country 是 USA 的,每一次只搜尋 5 筆(LIMIT 5)並根據 id 作為排序,而目前在第二頁(OFFSET 5):
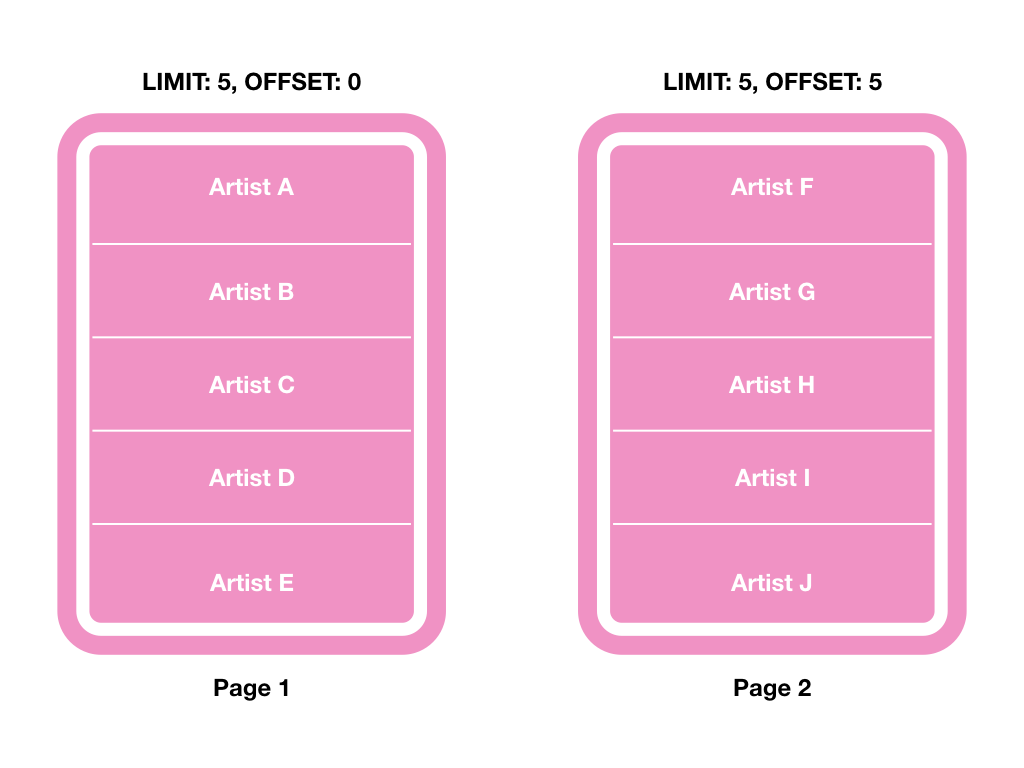
如上圖,假設 B 使用者目前位置是第 2 頁,當 A 使用者同時在某處新增 1 位藝人時,B 使用者有可會在下一頁(第 3 頁)又看到重複的藝人資料 Artist J,這是因為新增的資料會被排序到更前面(可能會在第一頁),所以會發現 OFFSET + LIMIT 不能有效地處理這類的情況。
當然 offsets 的方式還是有它的優點存在,例如:計算資料的總數量、目前頁數,或者是可以跳到指定的頁數。
Cursors
基於 Cursor 的分頁(Cursor-based pagination)是透過指定明確的起始點(Pointer)來回傳資料,這個方法解決了 OFFSET 方式的一些缺點,但是這需要一些取捨:
- Cursor 必須基於一個「唯一」或是「有序」的欄位(例如:
id或是created_at) - 它沒有「總和」和「頁數」的概念
在資料表中,這個「唯一」不一定是指單一的欄位,也可以是兩個欄位作為一個唯一。
將先前的範例改寫為使用 cursor-based 的分頁方式,以 id 作為 cursor 來取得資料,以下是取得第 1 頁的資料:
SELECT*FROMartistsWHEREcountry = 'USA'ORDER BYid DESCLIMIT 5 + 1;
應該注意到了在 LIMIT 的部分有一點不一樣,先前的範例中我們一頁想要取得 5 筆資料,但為什麼要加 1 呢?
💡 主要為了確定是否還有上(下)一頁的資料,但這一筆「多取得」的資料並不會回傳給 client 端
當處理完資料之後,這時候 server 會回傳類似如下的 response 給 client:
{"data": "[...]","cursor": "bd66b4d5c168b85676f38eeb9a4b0678"}
如上所述,cursor-based 它沒有「總和」和「頁數」的概念,因為每一次回來都是一個資料的集合。
Client 在收到 response 後,就可以在每一次的 request 中,藉由設定 cursor 和 limit 來繼續取得資料:
SELECT*FROMartistsWHEREcountry = 'USA'AND id <= $cursorORDER BYid DESCLIMIT $limit + 1;
與 offsets 的方式做比較,可以發現 cursors 解決了 offsets 的一些缺點:
- 藉由 cursors 可以很明確直接的指定資料的範圍從哪開始;相較於 offsets 需要讀取每一行直到設定的偏移量,這在資料量大時可以減少 database 的負荷。
- 對於 database 可能會被頻繁寫入資料的時候,offsets 可能會因為資料的新增或刪除造成資料的排序錯誤。
利用下圖作為一個情境,來解釋 cursors 是如何確保資料正確的排序:
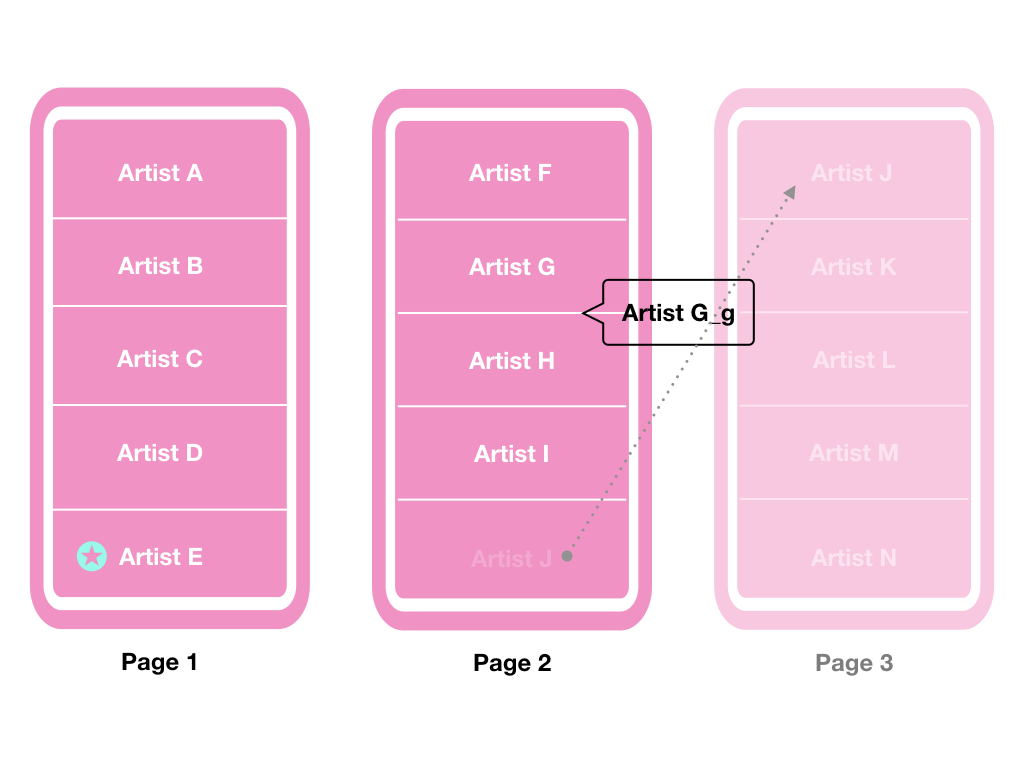
例如某 A 使用者剛進入到頁面(Page 1),他點擊了下一頁的按鈕,這時候會發出一個 request 透過 Artist E 的 cursor 去取得下一頁的資料,與此同時,某 B 使用者在別處新增了一個 Artist G_g,而它的 id 剛好位於 Artist G 以及 Artist H 之間,這時候從 Page 1 往下一頁拿 5 筆資料時,的排序應該會是:
Artist F | Artist G | Artist G_g | Artist H | Artist I
而 Artist J 則會因為新增的 Artist G_g 的關係,將會出現在第 3 頁。
Cursor Connections
根據 GraphQL 官方文件,可以得知在 GraphQL 中實作分頁會透過 cursor-based 的方式,通常會遵循 Relay Cursor Connections spec 來定義 GraphQL schema,以下幾個是必要的欄位:
Connection Type
- edges
- pageInfo
Edge Type
- node
- cursor
PageInfo
- hasNextPage
- hasPreviousPage
我用一個 Artist 的 schema 來作為一個簡單的範例:
type Artist {id: String!name: String!avatar: StringcreatedAt: DateTime!updatedAt: DateTime!}type ArtistsConnection {edges: [ArtistEdge!]!pageInfo: PageInfo!}type ArtistEdge {node: Artist!cursor: String!}type PageInfo {hasNextPage: Boolean!hasPreviousPage: Boolean!}
每一個分頁都是一個 Connection,Connection 底下會有許多的 Edge,而每個 Edge 都會有一個 Node,而這個 Node 也就是我們實際的資料,在這裡指的是 Artist,而 cursor 則是用來辨識 Edge,通常會將 cursor 做 encode,而 PageInfo 則是每一頁的資訊。
Pagination
Query String
以往在實作分頁,都會在網址上設計 query string(例如: https://foobar.com/?page=1)來方便的換頁,只要修改 page 後的數字就可以跳到指定的頁數。如前面所提到,這個實作通常是透過 offsets 的方式,所以你可以讓你隨心所欲換到想要的頁數,這裡推薦一下 Laravel Pagination 的文件,有興趣可以了解一下。
在 GraphQL 中,你不一定會將參數顯示在網址上,因為所有的參數很有可能都透過 GraphQL 的 query 一起被送出去(使用 POST 方式),不過還是要看 routing 是怎麼設計的,也許也有些參數需要在網址上,這一切都要看需求而去設計,沒有所謂的正確。
GitHub GraphQL API
GitHub 提供一個 GraphQL API Explorer,只要你有 GitHub 帳號,登入授權後就可以使用。例如你可以使用 curl 取得 GitHub 的個人資料:
$ curl \-X POST \-H "Content-Type: application/json" \-H "Authorization: bearer GithubAccessToken" \--data '{ "query": "{ viewer { name } " }' \https://api.github.com/graphql
-X代表的是 http 的 method-H代表的是 http 的 header--data代表的是要傳送的資料
下圖則是 GraphiQL 的互動介面:

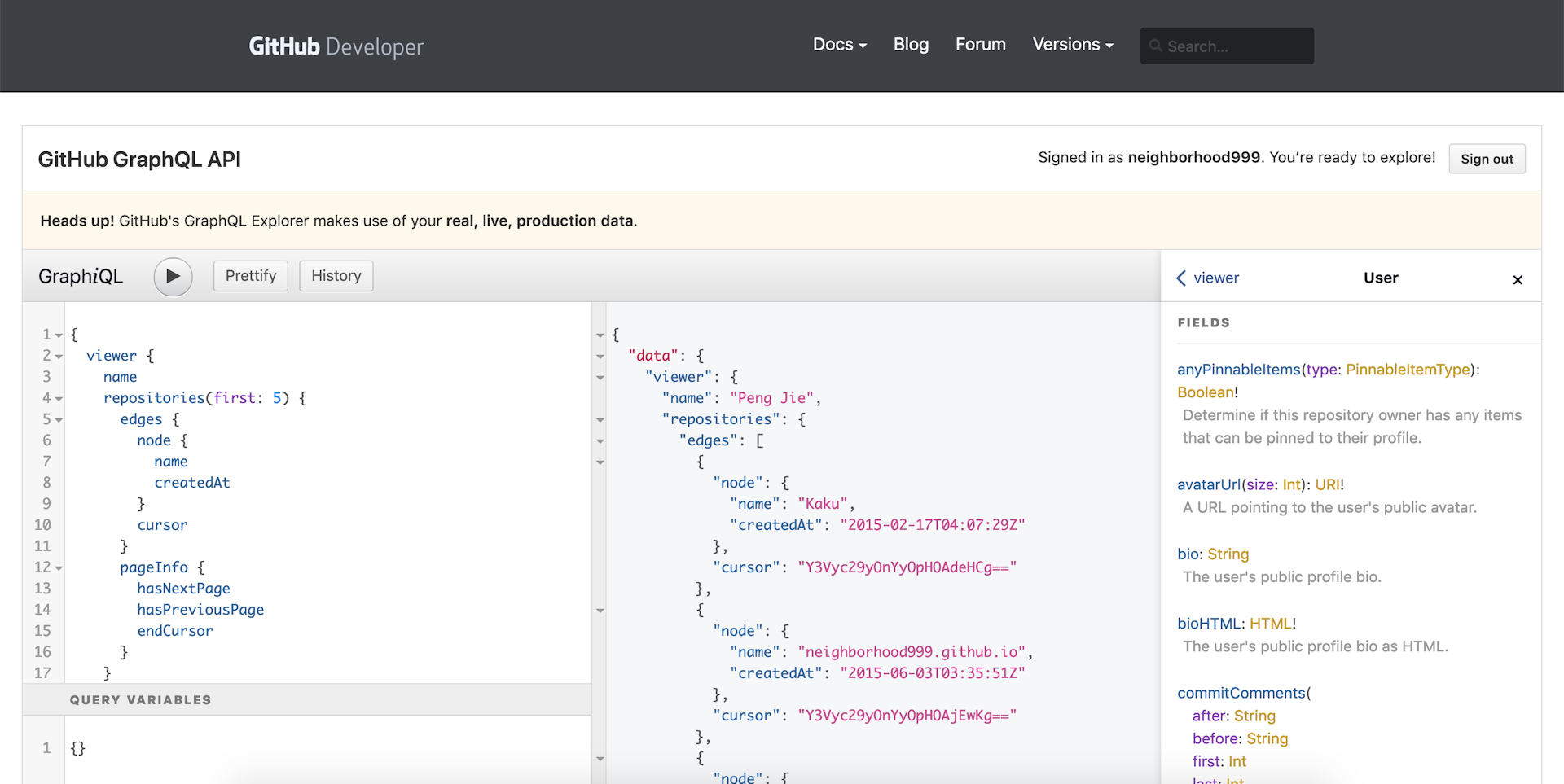
透過 GraphiQL 可以知道有哪些欄位是可以被查詢到的,本篇文章以 Pagination(分頁)作為主題,所以選了 repositories 來作為說明的範例,並且簡單分析 GitHub 如何實作 GraphQL Pagination。
首先,透過 Document Exploer 從 viewer 開始看起,你會發現 viewer 下有許多欄位,請往下捲動找到 repositories 的欄位:

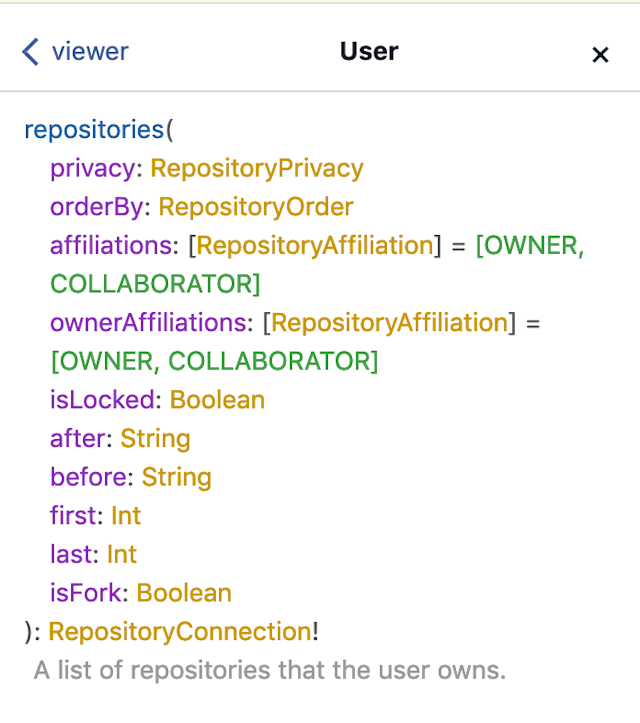
可以看到 repositories 提供了許多參數讓你可以輸入,而回傳的 type 是 RepositoryConnection,這符合了上方我們所提到的 Connection 的 schema 定義,點進去後可以看到:

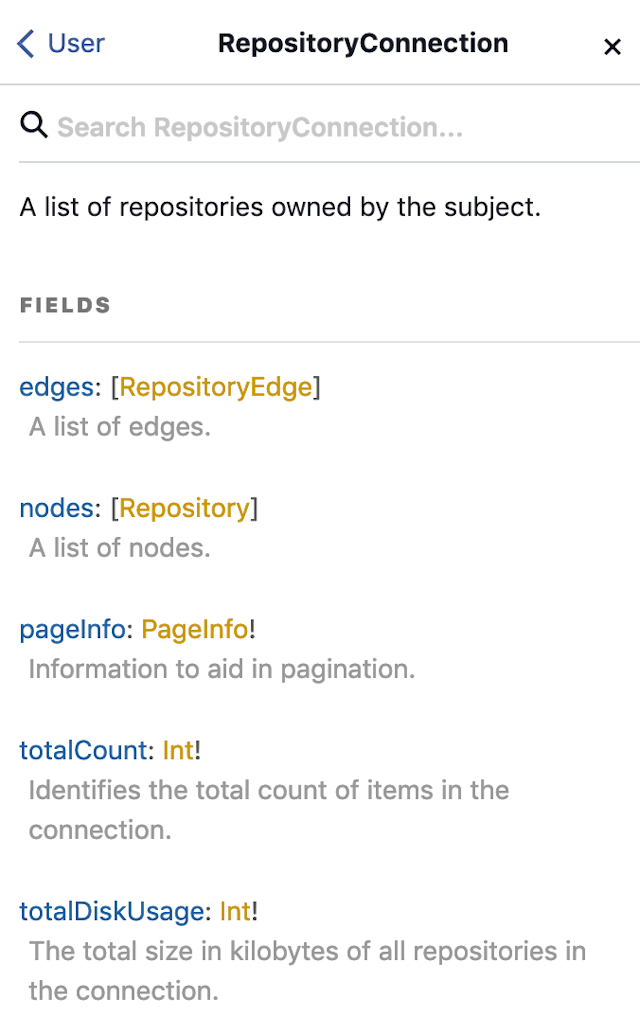
眼尖的你不知道有沒有注意到 edges 它並不是 required?這是不是跟上面所提到的規範好像不太一樣?實際在上實作的時候這些都是有彈性的,不一定要完整的遵循規範,所以像 GitHub 在實作這裡就採用了不同的方式。
除了上述規範提到的 edges 和 pageInfo 是必須的之外,其餘的欄位可以根據需求自行增加,如上圖可以看到還有其他像是 totalCount 等其他欄位。
在 GraphQL Pagination 中,會透過 first 或 last 來設定要取得的資料筆數,以 GitHub GraphQL API 作為範例:
{viewer {namerepositories(first: 3) {edges {node {namecreatedAt}cursor}pageInfo {hasNextPagehasPreviousPageendCursor}}}}
執行查詢後,可以拿回如下的資料:
{"data": {"viewer": {"name": "Peng Jie","repositories": {"edges": [{"node": {"name": "Kaku","createdAt": "2015-02-17T04:07:29Z"},"cursor": "Y3Vyc29yOnYyOpHOAdeHCg=="},{"node": {"name": "neighborhood999.github.io","createdAt": "2015-06-03T03:35:51Z"},"cursor": "Y3Vyc29yOnYyOpHOAjEwKg=="},{"node": {"name": "redux","createdAt": "2015-07-14T15:57:27Z"},"cursor": "Y3Vyc29yOnYyOpHOAlRj9g=="}],"pageInfo": {"hasNextPage": true,"hasPreviousPage": false,"endCursor": "Y3Vyc29yOnYyOpHOAlRj9g=="}}}}}
請仔細觀察資料的排序,是按照時間由舊至新,所以在這邊可以合理推測 repositories 的 first 實作可能是:
SELECT*FROMartistsORDER BYcreated_at ASCLIMIT $first;
💡
$first用來代表參數的意思。
反之如果使用 last 作為參數資料的排序則是按照時間由新至舊:
SELECT*FROMartistsORDER BYcreated_at DESCLIMIT $last;
在實作上對於資料的排序可以根據自己的需求做調整,例如你可能希望是由新到舊,那 first 的排序就應該是 DESC,而 last 的排序則是 ASC。
另外,GitHub GraphQL API 也提供了 orderBy 參數讓你可以自行調整資料的排序方式,這些在你實作時都可以考慮提供這些參數讓資料排序可以更加地彈性。
實作 GraphQL Pagination 後端
在開始前,先釐清一些基礎的觀念:
- 至少提供
first或last其中一個參數在查詢之中,不建議同時提供兩個參數進行查詢,這容易造成資料排序的混淆。 - 下一頁(Next Page):需要透過
first + after這兩個參數作為搭配,其中first需要為正整數,而after是接受一個 cursor type 的參數並使用最後一個 edge 的 cursor 來作為after。 - 上一頁(Previous Page):需要透過
last + before這兩個參數作為搭配,其中last需要為正整數,而before是接受一個 cursor type 的參數並使用第一個 edge 的 cursor 來作為before。
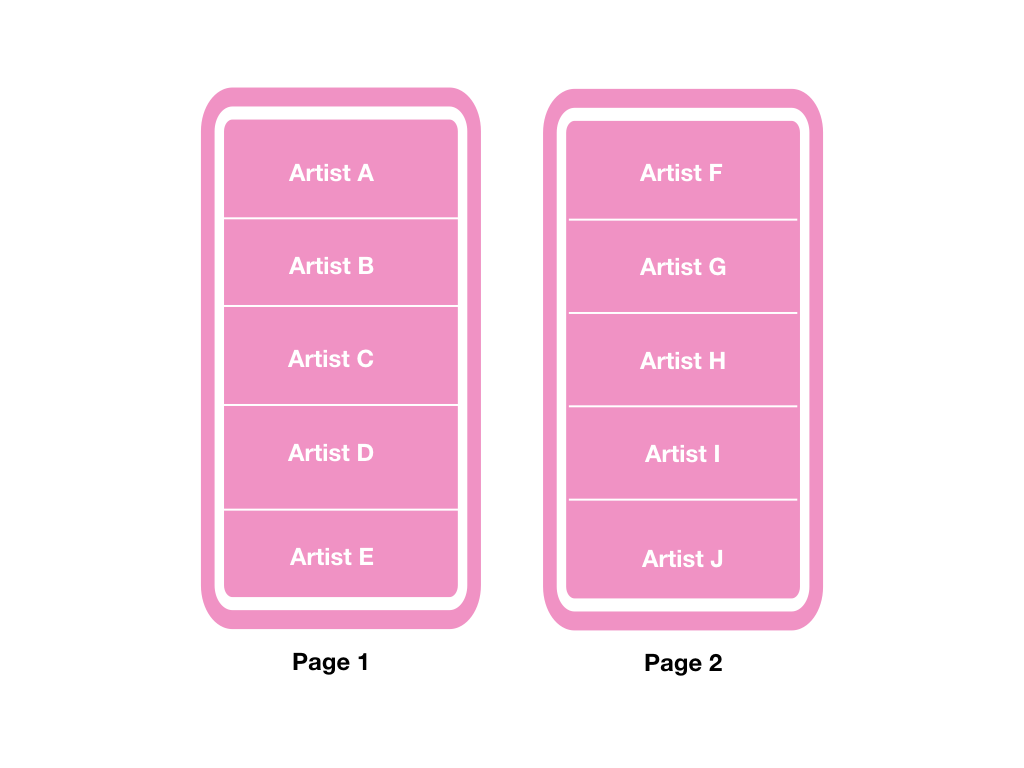
以上圖為例,一開始取得第一頁資料的時候會是:
{artists(first: 5) {edges {node {name}cursor}pageInfo {hasNextPagehasPreviousPageendCursor}}}
若要取得第二頁就必須透過 Artist E 的 cursor:
{artists(first: 5, cursor: $artistECursor) {edges {node {name}cursor}pageInfo {hasNextPagehasPreviousPageendCursor}}}
首先,在每次查詢的時候,至少都要提供 first 或 last 其中一個參數,作為你要取得資料的筆數,而官方不建議同時提供 first 以及 last 參數,因為它會造成導致混亂的查詢結果,當然它們所搭配的參數 after 和 before,也要避免同時存在。
所以在查詢時,先檢查這些相關的參數,並給予對應的錯誤處理或回應:
const resolver = {Query: {artists: async (root, args, context, info) => {const { first, last, after, before } = args;if (!first && !last) {/* Handling errors */}if (first && last) {/* Handling errors */}if (after && before) {/* Handling errors */}}}};
🔶 實作 first 的查詢
首先新增了三個參數:artists、hasNextPage、hasPreivousPage,它們是需要用到且是會變動的。
let artists;let hasNextPage;let hasPreviousPage;if (first && !after && !before) {const data = await knex('artists').orderBy('id', 'DESC').limit(first + 1);hasPreviousPage = false;hasNextPage = data.length > first;artists = hasNextPage ? data.slice(0, -1) : data;}
請注意到 SQL query builder 的 limit,前面已經提過,主要原因是為了確認是否還有下一頁(hasNextPage)的資料,接著看到程式下半部分:
hasPreviousPage = false;hasNextPage = data.length > first;artists = hasNextPage ? data.slice(0, -1) : data;
因為目前只有提供 first 的參數,所以可以很明確的知道目前就是在首頁,所以先將 hasPreviousPage 設定為 false,而取得的資料長度若大於給定的 first,則可以確定有下一頁,而實際上的資料則是要移除掉這一筆多取得的資料,first 部分簡單初步的實作就完成了。
🔶 實作 first + after 的查詢
if (first && after) {const data = await knex('artists').where('id', '<', decodeCursor(after)).orderBy('id', 'DESC').limit(first + 1);hasPreviousPage = true;hasNextPage = data.length > first;artists = hasNextPage ? data.slice(0, -1) : data;}
為了要取得下一頁的資料,將會需要 after cursor。通常 cursor 不會是一個 readable 的資料,前端看到的是被 encode 過的 cursor,直到傳到後端之後才被 decode。
仔細看可以發現實作和 first 相去不遠,差異在查詢以及頁面狀態的 flag。
在範例中是使用 id 作為排序的根據,從前端傳的 cursor 實際上到後端會被 decode,所以在這邊需要一個 decodeCursor 的 function 來 decode 傳入的 cursor。
當拿到實際的 cursor 後,將它放入在 where 的條件句,就可以指定明確的資料範圍了。
🔶 實作 last 的查詢
if (last && !before && !after) {const data = await knex('artists').orderBy('id', 'ASC').limit(last + 1);}
在實作 last 部分需要注意到資料排序的問題,因為 last 這邊是使用 ASC 對資料進行排序,也就是舊到新。
這裡牽扯到了「後端要回傳怎麼樣的資料給前端」,以 GitHub GraphQL API 為例:如果使用 first 是 ASC 排序,使用 last 會是 DESC 排序,以設計 API 來說沒有什麼問題;但以我上面的範例來說,如果 last 的排序沒有再做一層處理,而前端在接收到資料也沒有進行處理排序的話,那麼資料順序就會變得非常奇怪。
這麼說可能有點抽象,我用以下圖片來做解釋:
當我從 Page 1 到 Page 2 時,利用上方 first + after 的實作,可以拿到正確的資料排序:
當我要從 Page 2 再回到 Page 1 時,如果是用 ASC 的話,得到的排序結果會變成:
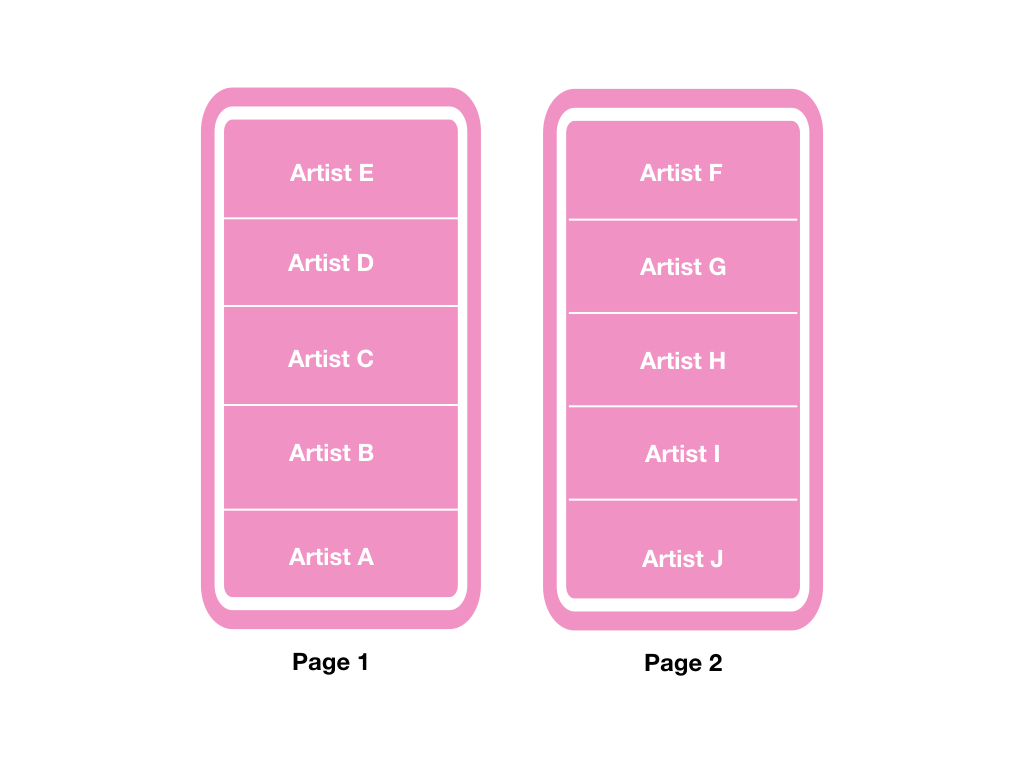
這裡的處理方式就是要看這個資料的排序要從後端處理,或者是由前端拿到資料後再進行排序的選擇,我自己是選擇前者來實作,也就是從後端直接處理,所以上面的查詢方式應該修改為:
if (last && !before && !after) {const subQuery = knex('artists').orderBy('id', 'ASC').limit(last + 1);const data = await knex.from(knex.raw(`(${subQuery}) AS artists`)).orderBy('artists.id', 'DESC');hasNextPage = false;hasPreviousPage = data.length > last;artists = hasPreviousPage ? data.slice(1) : data;}
可以看到我先寫了一個查詢式 subQuery,將它作為一個子查詢,概念上和 first 一樣,會多取得一筆來確定是否有前一頁(hasPreviousPage),接著再做一次資料的翻轉(DESC),最後再把這一筆多取得的資料給去除掉,這時候多餘的資料因為翻轉後會在第一個,所以要寫成 data.slice(1) 取得第一筆之後的資料。
🔶 實作 last + before 的查詢
if (last && before) {const subQuery = builder.where('id', '>', decodeCursor(before)).orderBy('id', 'ASC').limit(last + 1);const data = await knex.from(knex.raw(`(${subQuery}) AS artists`)).orderBy('artists.id', 'DESC');hasNextPage = true;hasPreviousPage = data.length > last;artists = hasPreviousPage ? data.slice(1) : data;}
上一頁查詢的部分,其實和上面 last 的概念一樣,只是多了 cursor 來指定資料範圍,可以參考 first + after 部分,就不再多作闡述。
整理一下以上的實作:
const resolver = {Query: {artists: async (root, args, context, info) => {const { first, last, after, before } = args;if (!first && !last) {/* Handling errors */}if (first && last) {/* Handling errors */}if (after && before) {/* Handling errors */}let artists;let hasNextPage;let hasPreviousPage;if (first && !after && !before) {const data = await knex('artists').orderBy('id', 'DESC').limit(first + 1);hasPreviousPage = false;hasNextPage = data.length > first;artists = hasNextPage ? data.slice(0, -1) : data;}if (first && after) {const data = await knex('artists').where('id', '<', decodeCursor(after)).orderBy('id', 'DESC').limit(first + 1);hasPreviousPage = true;hasNextPage = data.length > first;artists = hasNextPage ? data.slice(0, -1) : data;}if (last && !before && !after) {const subQuery = knex('artists').orderBy('id', 'ASC').limit(last + 1);const data = await knex.from(knex.raw(`(${subQuery}) AS artists`)).orderBy('artists.id', 'DESC');hasNextPage = false;hasPreviousPage = data.length > last;artists = hasPreviousPage ? data.slice(1) : data;}if (last && before) {const subQuery = builder.where('id', '>', decodeCursor(before)).orderBy('id', 'ASC').limit(last + 1);const data = await knex.from(knex.raw(`(${subQuery}) AS artists`)).orderBy('artists.id', 'DESC');hasNextPage = true;hasPreviousPage = data.length > last;artists = hasPreviousPage ? data.slice(1) : data;}return {edges: artists,pageInfo: {hasNextPage,hasPreviousPage}};}}};
最後記得要回傳 ArtistsConnection 所要求的 edges、pageInfo 的資料。
前端整合
如果是使用 apollograhql 的話,可以透過 fetchMore 的 function 可以讓你輕鬆的取得上(下)頁的資料,例如取得下一頁:
fetchMore({query: YOUR_QUERY,variables: {first: 5,after: 'first cursor'},updateQuery: (previousResult, { fetchMoreResult }) => {/*...*/}});
💬 踩雷經驗
時間精度
在 JavaScript 中,要取得 ISO 的時間格式,可以透過 toISOString 的 function 取得:
console.log(new Date.toISOString()); // 2019-12-06T07:50:35.816Z
這是簡化的 ISO 8601 時間格式,尾綴的 Z 表示為世界標準時間,詳細可以參考 MDN - Date.prototype.toISOString() 說明。
從上面列印的結果,可以知道 JavaScript 的時間精度只能表示到毫秒(millisecond),也就是小數點後 3 位。
目前公司是使用 PostgreSQL 作為資料庫,而 PostgreSQL 的 時間精度可以表示到微秒(microsecond)。
一開始不了解 PostgreSQL 和 JavaScript 它們的時間精度差異,所以使用了 created_at 作為 cursor 來使用,例如前端拿回了以下的 data:
{"data": {"artists": {"edges": [{"node": {"name": "Artist A",},"cursor": "b4582d31b37192f1067ff129a3854bbb"},{"node": {"name": "Artist B"},"cursor": "34e6d858e1acdb3e66209178c225d3b1"},{"node": {"name": "Artist C"},"cursor": "d8f0c4abacdccd3719f6abf3aa7ec1e5"}],"pageInfo": {"hasNextPage": true,"hasPreviousPage": false,"startCursor": "b4582d31b37192f1067ff129a3854bbb","endCursor": "d8f0c4abacdccd3719f6abf3aa7ec1e5"}}}}
每個 cursor 實際上都是 created_at 被 encode 的結果,pageInfo 的 startCursor 和 endCursor 這兩個欄位分別是 artists 資料集的頭和尾 cursor。
接著可以拿其中的一個 cursor 透過 fetchMore 去取得上(下)頁的資料,這些 cursor 傳到後端後會被 decode 得到原先的資料(created_at)。
接著看到後端方面,從資料庫查詢出來的 created_at,它的時間如下:
2019-12-07 04:09:56.994393
時間精度可以到「微秒」。
通常 cursor 可以用 node 內建的 Buffer 來將時間給 encode 和 decode,例如:
Buffer.from('2019-12-07 04:09:56.994393Z').toString('base64'); // MjAxOS0xMi0wNyAwNDowOTo1Ni45OTQzOTNa
而當時我做了一個致命的動作,就是將這個時間又用 JavaScript 的 new Date 做了一次:
Buffer.from(new Date('2019-12-07 04:09:56.994393Z').toISOString()).toString('base64'); // MjAxOS0xMi0wN1QwNDowOTo1Ni45OTRa
接著,將以上這兩種方式給 decode 回來比較:
Buffer.from('MjAxOS0xMi0wNyAwNDowOTo1Ni45OTQzOTNa', 'base64').toString('ascii'); // 2019-12-07 04:09:56.994393ZBuffer.from('MjAxOS0xMi0wNlQyMDowOTo1Ni45OTRa', 'base64').toString('ascii') // 2019-12-06T20:09:56.994Z
發現 decode 回來的結果是不同的,可以看到使用 new Date 方式的時間,時間單位只有到毫秒,這就是問題所在。
如果你用後者的時間來作為 cursor,這一筆資料很有可能會重複出現,原因是 2019-12-07 04:09:56.994393Z 的時間相較於 2019-12-06T20:09:56.994Z 是相對較新的,後者其實可以將它看成 2019-12-06T20:09:56.994000Z,所以在資料庫查詢時,原本被作為 cursor 的這一筆資料會被重複查出來,造成資料的排序錯誤。